Introduction
L’intelligence artificielle et le Machine Learning sont des domaines en pleine croissance. Dans ce tutoriel, nous allons vous guider pas à pas pour créer votre premier modèle de Machine Learning en utilisant Python et Scikit-learn. Que vous soyez un débutant ou que vous ayez des connaissances avancées, ce guide pratique est fait pour vous.
Sommaire

Comprendre les bases
Avant de s’immerger dans le processus complexe et fascinant de la création de modèles, il est indispensable de saisir les fondements du Machine Learning, ou apprentissage automatique. Cette notion, de plus en plus répandue dans notre monde technologique en constante évolution, nécessite une compréhension solide de ses principes de base pour quiconque souhaite explorer ses potentialités et tirer profit de ses applications pratiques. Le Machine Learning est un sous-ensemble de l’intelligence artificielle qui se concentre sur la construction de systèmes capables d’apprendre à partir de données, sans être explicitement programmés pour cela. Cette capacité d’apprentissage permet aux machines de s’adapter et d’évoluer en fonction de nouvelles informations, rendant ainsi les systèmes plus efficaces et flexibles. Mais avant de pouvoir créer des modèles efficaces, il est crucial de maîtriser les fondations sur lesquelles le Machine Learning repose. L’une de ces fondations est la connaissance des différents types d’algorithmes de Machine Learning.
Quels algorithmes d’apprentissage automatique ?
Ces algorithmes, qui sont au cœur de tout système d’apprentissage automatique, sont classés en plusieurs catégories, notamment l’apprentissage supervisé, l’apprentissage non supervisé, l’apprentissage semi-supervisé et l’apprentissage par renforcement. Chaque type d’algorithme a ses particularités, ses avantages et ses inconvénients, et est adapté à des situations et des problèmes spécifiques. Comprendre ces différences et savoir quand et comment utiliser chaque type d’algorithme est une compétence clé pour tout praticien du Machine Learning. En outre, une autre base fondamentale du Machine Learning est la connaissance des jeux de données. Les données sont le carburant des systèmes d’apprentissage automatique : elles alimentent les algorithmes et permettent aux machines d’apprendre. Comprendre les différents types de données, savoir comment les collecter, les nettoyer, les préparer et les utiliser efficacement est essentiel pour la création de modèles de Machine Learning performants. Enfin, il est important de comprendre les problèmes que le Machine Learning peut résoudre.
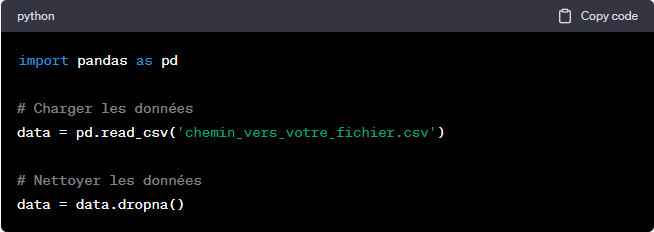
Étape 1: Préparation des données
Outils: Python, Pandas
La préparation des données est une partie cruciale du processus. Cela implique de collecter des données, de les nettoyer et de les organiser de manière à ce qu’elles puissent être utilisées efficacement par les algorithmes de Machine Learning. Python est un excellent langage pour cela, et la bibliothèque Pandas est particulièrement utile pour manipuler des données.
Étape 2: Choisir un algorithme
Outil: Scikit-learn
Il existe de nombreux algorithmes de Machine Learning, et choisir le bon dépend du type de problème que vous essayez de résoudre. Scikit-learn est une bibliothèque Python qui offre une grande variété d’algorithmes.
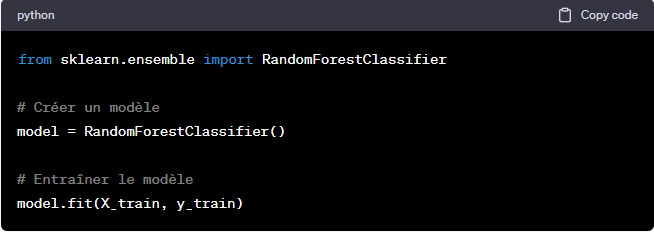
Étape 3: Entraîner le modèle
Outil: Scikit-learn
Une fois que vous avez préparé vos données et choisi un algorithme, il est temps d’entraîner votre modèle. Utilisez Scikit-learn pour cela.
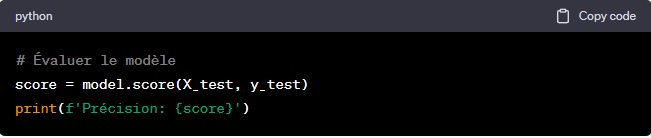
Étape 4: Évaluer et optimiser
Outil: Scikit-learn
Après avoir entraîné votre modèle, il est important de l’évaluer pour s’assurer qu’il fonctionne correctement. Utilisez Scikit-learn pour évaluer les performances de votre modèle.
Conclusion
Créer votre premier modèle de Machine Learning peut sembler intimidant, mais avec les bons outils et une compréhension des étapes clés, c’est un défi réalisable. Python et Scikit-learn sont d’excellents outils pour commencer. N’oubliez pas que la pratique est essentielle, alors commencez dès aujourd’hui et explorez les nombreuses possibilités que le Machine Learning offre.


