🎯🔍Ensembling en IA: Définition et Fonctionnement
Introduction
Dans le domaine de la gestion des données et du machine learning, nous sommes confrontés à une variété de modèles et de méthodes visant à optimiser l’exploitation de l’information. L’Ensembling ou Méthodes d’Ensemble, une technique qui combine plusieurs algorithmes d’apprentissage pour obtenir de meilleurs résultats prédictifs, est un concept qui gagne en popularité. C’est une approche qui a fait ses preuves et qui peut considérablement améliorer la performance de votre système. Mais qu’est-ce que l’Ensembling, et comment cela fonctionne-t-il ? C’est ce que nous allons détailler dans cet article.
Comprendre l’Ensembling
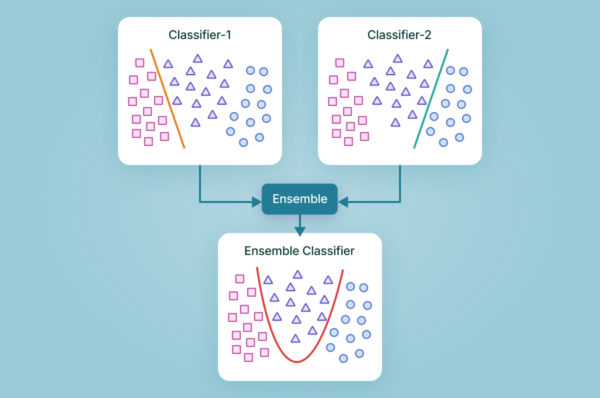
L’idée principale derrière l’Ensembling ou Méthodes d’Ensemble est de combiner les prédictions de plusieurs modèles d’apprentissage afin de générer une prédiction finale plus précise. C’est un peu comme si vous consultiez plusieurs experts dans un domaine donné pour obtenir un avis équilibré.
Dans le contexte des Méthodes d’Ensemble, chaque “expert” est un algorithme d’apprentissage différent, et l’avis “équilibré” est la prédiction finale, obtenue en combinant les prédictions de chaque expert. L’Ensembling peut être utilisé dans divers domaines d’application, notamment la reconnaissance d’images, la détection d’anomalies, la prédiction de séries temporelles et bien d’autres.
Les différents types d’Ensembling
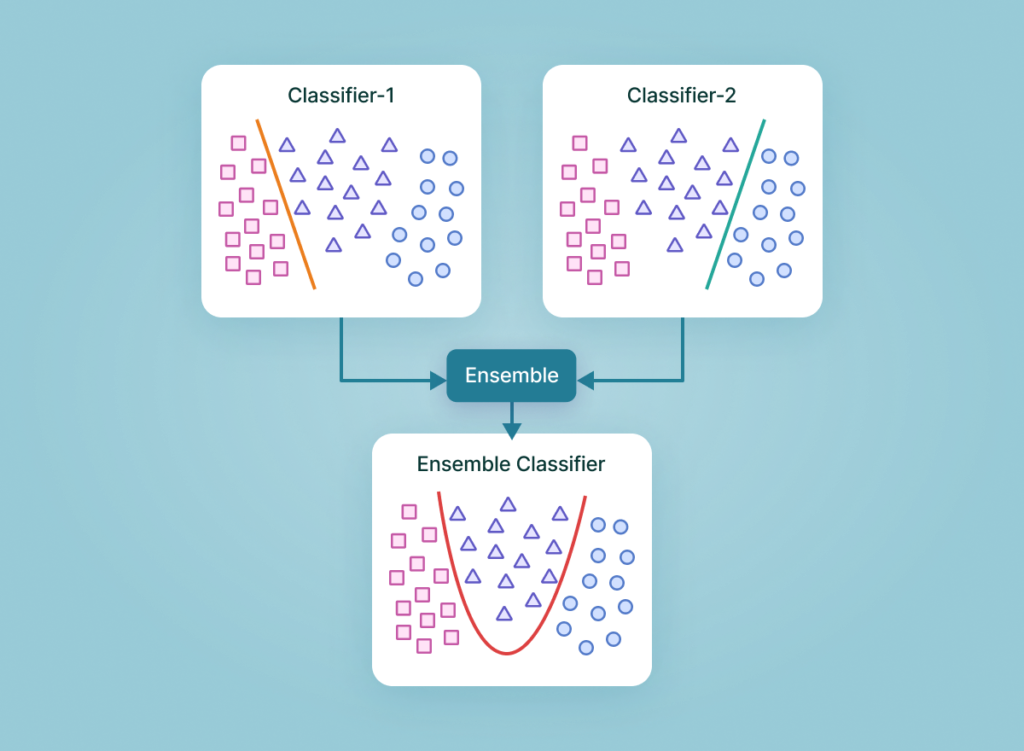
Il existe principalement trois types d’Ensembling : le bagging, le boosting et le stacking. Chaque type utilise une approche différente pour combiner les prédictions de plusieurs algorithmes, offrant ainsi une flexibilité dans le développement de systèmes de prévision.
Le Bagging, ou bootstrap aggregating, est une méthode qui génère plusieurs sous-ensembles de données à partir de l’ensemble de données d’origine, avec remplacement. Chaque sous-ensemble est utilisé pour entraîner un modèle différent, et les prédictions de tous les modèles sont ensuite combinées pour obtenir le résultat final.
Le Boosting, au contraire, est une méthode séquentielle où chaque modèle est formé pour corriger les erreurs commises par le modèle précédent. Le modèle final est une combinaison pondérée des prédictions de tous les modèles.
Le Stacking, quant à lui, est une approche qui combine les prédictions de plusieurs modèles différents, formés avec différentes méthodes d’apprentissage, pour générer une prédiction finale.

Comment se déroule l’apprentissage en Ensembling
Les Méthodes d’Ensemble reposent sur l’idée que plusieurs têtes pensent mieux qu’une. Lors de l’apprentissage en Ensembling, plusieurs algorithmes d’apprentissage sont formés séparément, puis leurs prédictions sont combinées d’une certaine manière pour produire le résultat final.
Le processus exact varie en fonction du type d’Ensembling utilisé – bagging, boosting ou stacking. Toutefois, dans tous les cas, le processus d’apprentissage implique la formation de plusieurs modèles et la combinaison de leurs prédictions.
L’Ensembling dans le développement de modèles prédictifs
L’utilisation de l’Ensembling dans le développement de modèles prédictifs peut offrir plusieurs avantages. Premièrement, elle peut améliorer la précision des prédictions en combinant les forces de plusieurs algorithmes d’apprentissage. Deuxièmement, elle peut aider à atténuer les problèmes tels que le surapprentissage, où un modèle s’ajuste trop étroitement aux données d’entraînement et perd sa capacité à généraliser à partir de nouvelles données.
Toutefois, l’Ensembling a aussi ses inconvénients. Il nécessite plus de ressources informatiques et peut être plus difficile à interpréter que les modèles individuels. De plus, il n’est pas toujours garanti que l’Ensembling conduira à de meilleures performances – tout dépend du problème spécifique et des algorithmes utilisés.
L’Ensembling en action : une visite guidée
Pour comprendre concrètement comment fonctionne l’Ensembling, prenons l’exemple d’un problème de classification. Supposons que nous voulions utiliser l’intelligence artificielle pour déterminer si un client est susceptible ou non de souscrire à un nouveau service.
Nous pourrions commencer par former plusieurs algorithmes d’apprentissage individuels, tels que des arbres de décision, des réseaux de neurones, et des modèles de régression linéaire. Chaque algorithme serait formé sur les données d’entraînement et produirait une prédiction indépendante.
Ensuite, nous utiliserions une technique d’Ensembling pour combiner ces prédictions. Par exemple, avec le bagging, nous pourrions utiliser un vote majoritaire pour déterminer la prédiction finale. Avec le boosting, chaque algorithme pourrait être pondéré en fonction de sa précision, et ces poids seraient utilisés pour déterminer la prédiction finale. Enfin, avec le stacking, un autre algorithme d’apprentissage serait formé pour combiner les prédictions des autres algorithmes.
Bien sûr, ceci n’est qu’un exemple simplifié. Dans la pratique, le processus peut être beaucoup plus complexe et impliquer une multitude d’algorithmes et de techniques.
Application de l’Ensembling dans l’industrie
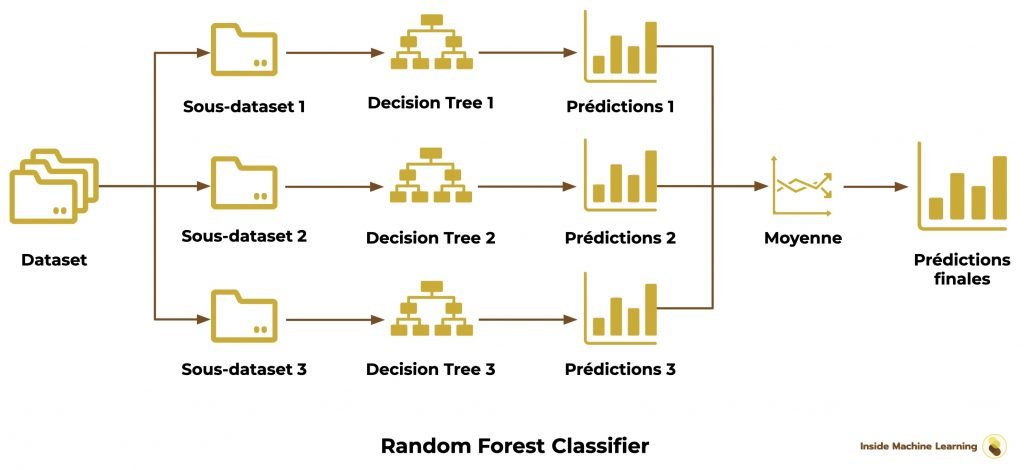
L’Ensembling est largement utilisé dans l’industrie pour améliorer les performances des systèmes de prédiction. Par exemple, le modèle populaire Random Forest est une forme de bagging où de nombreux arbres de décision sont formés et leurs prédictions sont combinées.
Dans le domaine du deep learning, l’Ensembling est également couramment utilisé pour améliorer la robustesse et la précision des réseaux de neurones. En effet, plusieurs “weak learners” (des modèles simples qui ne font guère mieux que le hasard) sont combinés pour former un “strong learner” (un modèle qui fait nettement mieux que le hasard).
L’Ensembling peut également être utilisé dans le domaine du service client, où plusieurs algorithmes peuvent être formés pour prédire le comportement des clients et informer les décisions stratégiques.
Conclusion
En résumé, l’Ensembling est une technique d’apprentissage de machine puissante qui peut améliorer considérablement la précision des prédictions. Sa force réside dans sa capacité à combiner les forces de plusieurs algorithmes d’apprentissage, tout en minimisant leurs faiblesses.
Toutefois, il est important de garder à l’esprit que l’Ensembling n’est pas une solution miracle. Son efficacité dépendra de la qualité de vos données, de la pertinence de vos algorithmes d’apprentissage et de votre capacité à choisir la bonne méthode d’Ensembling pour votre problème spécifique. C’est là que l’expertise de votre équipe se révélera précieuse.
Ainsi, l’Ensembling est un puissant outil à ajouter à votre boîte à outils d’apprentissage de machine. Avec une bonne compréhension de ses principes et une application judicieuse, il peut vous aider à atteindre des niveaux de performance que vous n’auriez jamais pu atteindre avec des modèles individuels.

