Introduction
Les modèles de langage large (LLM) sont des outils puissants qui ont révolutionné le domaine de l’intelligence artificielle (IA). Ces modèles, basés sur des réseaux neuronaux, ont la capacité d’apprendre à partir de vastes quantités de données textuelles pour générer du texte, répondre à des questions, et bien plus encore. Avec l’émergence de modèles LLM open source, il est désormais possible pour les chercheurs, les développeurs et les enthousiastes de l’IA d’explorer et de bénéficier de ces technologies prometteuses.
Sommaire
Dans cet article, nous explorerons les cinq meilleurs LLM open source qui ont fait leurs preuves en septembre 2023. Chaque modèle apporte ses propres forces et capacités uniques, offrant une multitude de possibilités dans le domaine de l’IA générative. Nous examinerons en détail les modèles Falcon, Llama2, MPT, FastChat-T5 et OpenLLaMA, en mettant en évidence leurs caractéristiques clés, leurs performances et leurs applications potentielles.
Falcon: Un LLM puissant pour la génération de texte
L’Institut de l’Innovation Technologique d’Abu Dhabi a développé le modèle Falcon, un LLM. Actuellement, ce modèle occupe la première place dans le classement Open LLM LeaderBoard de Hugging Face et présente une architecture de décodage uniquement.Le modèle Falcon-40B dispose de 40 milliards de paramètres, tandis que le modèle Falcon-7B est une version plus légère avec 7 milliards de paramètres.
L’un des points forts de Falcon réside dans la qualité de ses données d’entraînement. L’Institut de l’Innovation Technologique d’Abu Dhabi a formé le modèle sur le jeu de données RefinedWeb, extrait du web et filtré pour assurer des résultats de haute qualité. Grâce à cette approche unique, Falcon atteint des performances supérieures à celles d’autres modèles similaires, tout en utilisant seulement environ 75% du budget de calcul d’entraînement de GPT-3.
L’Institut de l’Innovation Technologique d’Abu Dhabi a conçu Falcon pour être particulièrement efficace dans la génération de texte de qualité, la réponse aux questions et la traduction de langues. Les entreprises peuvent utiliser ce modèle pour diverses applications, telles que les systèmes de support client, les plates-formes interactives et les assistants virtuels.
L’Institut de l’Innovation Technologique d’Abu Dhabi recommande d’utiliser une carte graphique avec une RAM de 15 à 20 Go, comme la Nvidia A10G, pour exploiter Falcon.Pour les applications nécessitant plus de puissance, il existe également le modèle Falcon-40B, qui nécessite une carte graphique avec une RAM de 45 Go.
Llama2: Une évolution majeure dans le domaine des chatbots
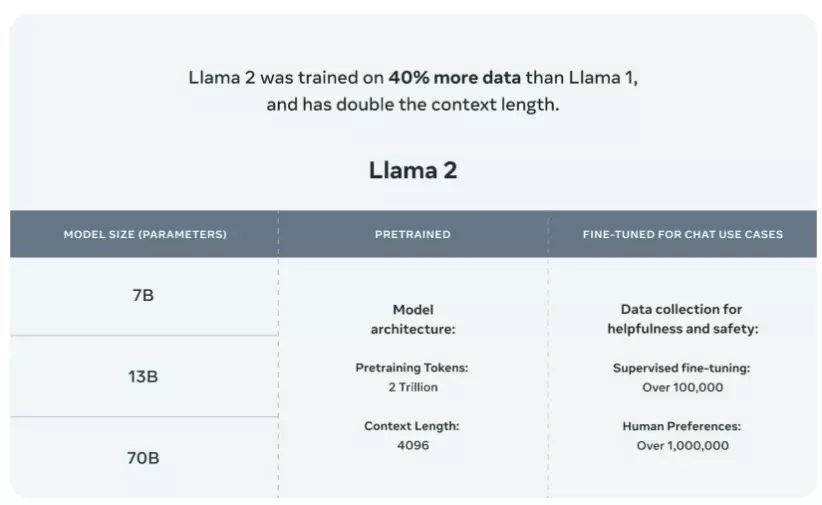
En partenariat avec Microsoft, Meta a créé Llama2, un modèle LLM. Ce modèle, qui succède au modèle Llama original, représente une avancée significative dans le domaine des chatbots. L’accès au modèle Llama original, pionnier dans la génération de texte et de code, était limité pour éviter les abus. Par contre, Llama2 a été conçu pour atteindre un plus grand nombre d’utilisateurs.
L’une des caractéristiques clés de Llama2 est sa diversité en termes de données d’entraînement. Des chercheurs ont formé le modèle sur un ensemble de données vaste et varié, lui donnant ainsi une compréhension approfondie et des performances de qualité. De plus, la collaboration entre Meta et Microsoft a permis d’intégrer Llama2 sur des plateformes comme Azure et Windows, rendant le modèle accessible aux développeurs et aux organisations.
Avec la sécurité en tête de liste des priorités, Meta a développé Llama2. Ils ont instauré des mesures rigoureuses pour minimiser les « hallucinations« , la désinformation et les biais du modèle. Alors que le Llama original a été formé sur 1,4 billion de jetons, Meta a entraîné Llama2 sur deux millions de jetons, montrant ainsi une nette augmentation.
Llama2 est disponible sur des plateformes telles que AWS, Azure et la plateforme d’hébergement de modèles d’IA de Hugging Face. En outre, grâce à la collaboration entre Meta et Microsoft, les appareils équipés du système sur puce Qualcomm Snapdragon peuvent aussi prendre en charge Llama2.
MPT: Des modèles LLM polyvalents pour des tâches avancées
MosaicML a développé les modèles MPT comme des LLM qui utilisent uniquement une architecture de décodage. Ils ont formé ces modèles sur un ensemble de données varié contenant 1 billion de jetons de texte et de code. Ils offrent donc une polyvalence exceptionnelle pour une variété de tâches avancées.
MPT-30B est le modèle phare de la série MPT, avec 30 milliards de paramètres. Il s’agit du premier LLM connu formé sur les cartes graphiques NVIDIA H100. MPT-7B, quant à lui, est une version plus légère avec 7 milliards de paramètres, offrant une alternative plus légère pour les tâches moins exigeantes en ressources.
Des experts ont formé ces modèles MPT pour des tâches spécifiques comme la génération de code, la compréhension de lecture et la résolution de problèmes. Vous pouvez les utiliser comme modèles autonomes ou comme bases pour développer des modèles spécialisés.
Pour l’inférence, vous devez utiliser une carte graphique NVIDIA A100 avec une RAM de 80 Go pour MPT-30B, tandis que pour MPT-7B, une carte graphique NVIDIA A10G avec une RAM de 15 à 20 Go suffit.
FastChat-T5: Un modèle LLM pour des applications conversationnelles
L’équipe de FastChat a développé FastChat-T5, un modèle LLM. Ils ont basé ce modèle sur l’ajustement fin du modèle Flan-T5-XL, un grand modèle transformer doté de 3 milliards de paramètres. Le modèle FastChat-T5 est conçu pour générer des réponses aux entrées des utilisateurs de manière autonome.
L’architecture de FastChat-T5 est un modèle transformer de type encodeur-décodeur. Le modèle encode de manière bidirectionnelle la question de l’utilisateur pour obtenir une représentation cachée, puis le décodeur utilise l’attention croisée pour se concentrer sur cette représentation et générer une réponse unidirectionnelle à partir d’un jeton de départ.
FastChat-T5 est conçu spécifiquement pour les applications de chatbots et les systèmes de génération de texte conversationnel. Vous pouvez l’employer dans divers domaines comme le support client, les plates-formes interactives et les assistants virtuels. Une carte graphique avec une RAM de 15 Go est recommandée pour utiliser le modèle FastChat-T5.
OpenLLaMA: Une reproduction du modèle LLM LLaMA de Meta
Berkeley AI Research a développé OpenLLaMA comme une version open source du modèle LLaMA de Meta. Ils ont publié ce modèle sous la licence Apache 2.0, le rendant entièrement open source. Ils ont conçu OpenLLaMA pour être une alternative plus accessible et modifiable au modèle LLaMA original.
Les chercheurs ont formé OpenLLaMA en suivant le même processus que le modèle LLaMA original, mais ils ont utilisé des jeux de données publics pour assurer la transparence et l’accessibilité. Ce modèle excelle dans des tâches comme la génération de texte, la création de résumés et la traduction.
Pour utiliser OpenLLaMA, une carte graphique avec une RAM de 15 à 20 Go est recommandée. Sa flexibilité et sa capacité de personnalisation supérieures au modèle LLaMA original le rendent particulièrement séduisant pour les chercheurs et les développeurs.
Conclusion
Les modèles LLM open source offrent une multitude de possibilités dans le domaine de l’IA générative. Que vous optiez pour Falcon pour sa capacité impressionnante de génération de texte, Llama2 pour ses compétences en matière de chatbot, MPT pour ses fonctionnalités avancées, FastChat-T5 pour des dialogues naturels ou OpenLLaMA comme alternative ouverte, soyez sûr d’utiliser des outils de pointe pour vos initiatives en intelligence artificielle.
Ces modèles, avec leurs caractéristiques uniques, leurs performances élevées et leurs applications diverses, ouvrent de nouvelles perspectives passionnantes dans le domaine de l’IA. Que vous soyez un chercheur, un développeur ou simplement curieux de l’IA générative, il n’y a jamais eu de meilleur moment pour explorer les LLM open source et découvrir les possibilités infinies qu’ils offrent.


